dazzling_kalam
The Common Crawl (CC) www.commoncrawl.org project is very interesting.
CC crawls the Internet and stores the crawled data in specialized formats that are easy to read and process. Data has been crawled and stored since 2014.
There is a lot of information on their site and you should definitely explore this dataset. The project’s GitHub page has a lot of code to help you process the dataset at scale.
For e.g., https://github.com/commoncrawl/cc-pyspark has a great set of examples of how you can process CC data with PySpark.
For this chapter, I’ll show you how to parse WARC files. This is one of the formats provided by CC where the website HTML source is preserved.
WET files, another format, provides website content text without the HTML source. Since we want to extract the Javascript libraries being used, we will use the WARC files.
The data crawled is huge. Many TBs. CC Project has done a great job organizing this data.
Each WARC file has a name and there is a file that contains the names of all the 80,000 WARC files. This is the first step. Once you download the list of 80,000 WARC files, you can download them one by one or in parallel.
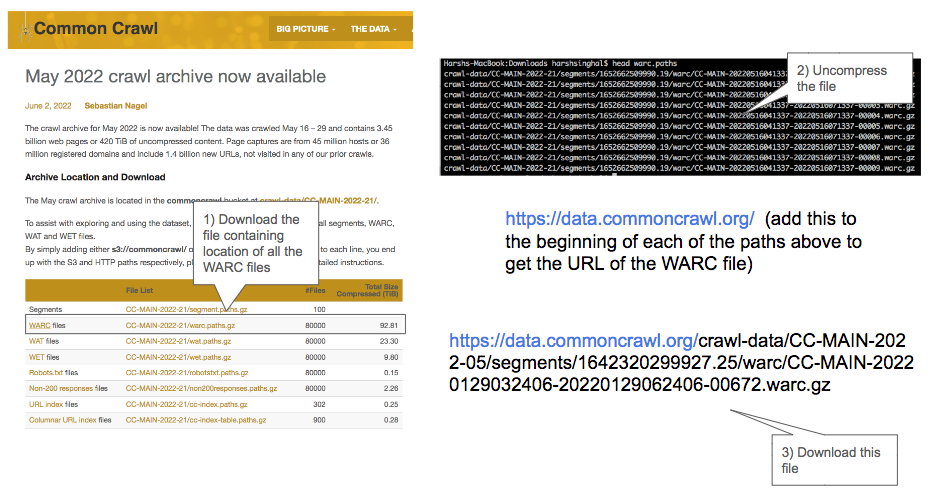
The steps you have to follow to figure out how to download a WARC file is;
- Get hold of the file that contains the paths of each
WARCfile - This path needs to be prefixed with
https://data.commoncrawl.org/and you can then issue awgeton it to download theWARCfile - Once you download the
WARCfile you can uncompress it and start to process it. EachWARCfile is ~ 1GB compressed and expands to ~4x to 5x when you uncompress it.
Here is a Kaggle notebook that shows you each step https://www.kaggle.com/harshsinghal/download-sample-warc-files-common-crawl
The code snippet below is taken from the above notebook and shows you how you can process a single WARC file.
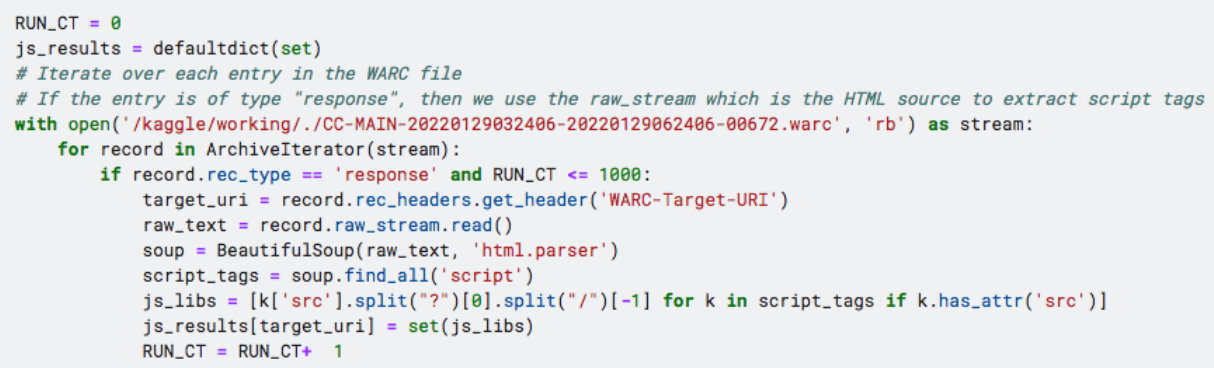
In the above snippet, we are going through each record in the WARC file. Each record contains the HTML source of a single URL.
The structure of the record is such that some pieces of information are directly accessible, such as the URL itself and a few other items. You can see an example WARC file here
The HTML source, which is what we are interested in needs to be parsed using a parser library. I’ve used BeautifulSoup which is one of the most popular HTML parsing libraries in Python.
With a few lines of code, BeautifulSoup will let you extract relevant details from the HTML source.
Easy.
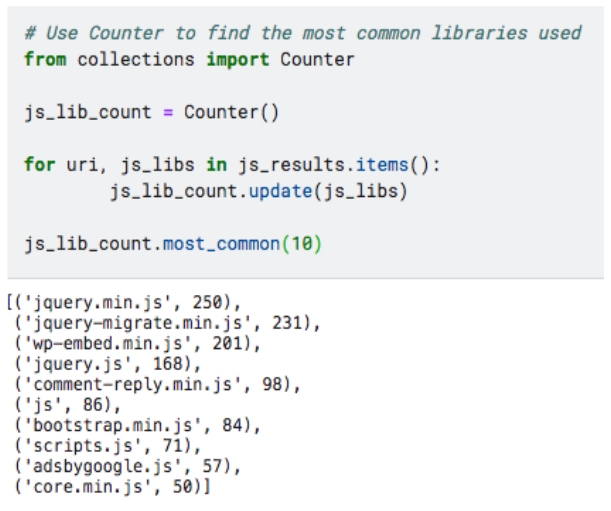
I only processed 1000 entries (you can parse more) from the WARC file and stored the results to analyze later.
The most frequent libraries are the usual names of jquery, bootstrap, and adsbygoogle.
How do I process more WARC files? Can I scale it in any way? Well, the PySpark approach is one way to scale it.
The approach exploits the idea of parallel processing.
We can process each WARC file in parallel. There is no need to do it one by one. In such cases of embarrassingly parallel problems, you can use many workers that are performing the task simultaneously.
Examples of embarrassingly parallel problems exist all around us.
Imagine a call center. Let us assume there is only one task to be done by the call center agents. If there are 10 agents and thousands of callers, how would you organize the agents? How would you route the calls to these agents? What happens when all 10 agents are busy and some customers are still waiting for their call to be answered?
You could hire a manager and have the manager receive all the calls from customers. This would protect the agents from being bombarded with calls.
The manager would then decide how to route the calls to each of the agents in a way where each agent can focus on a task, complete it and then take up the next task.
The above is an oversimplification (and a bad one) of parallel processing.
If you want to process all the WARC files and construct your own processing engine, you could use a similar approach as a call-center pattern of a manager and agents.
- Create a manager
- Give the manager the location of the
WARCfiles we wish to process - Create a few agents or workers
- Have the manager assign tasks to the workers
- The task to be performed by each worker is the following;
- Receive the
WARCfile location from the manager - Download the file
- Uncompress the file
- Iterate over each entry in the uncompressed
WARCfile. Each entry is a URL or a website. - Parse the raw
HTMLsource usingBeautifulSoup - Extract the
Javascriptlibraries used - Write the results to an output file
- Receive the
All we care about is that the manager does not give the same WARC file to more than 1 worker. That would mean we are processing the WARC file twice which is a waste of resources.
And we need to ensure that once a worker processes the file, they are not sitting idle.
A lot more moving parts and concerns need to be dealt with in a mature distributed computing system. We will not get into that and you can find a lot of great resources online.
I tried a few approaches based on the pattern described above.
The first approach I tried was to put all the WARC file names in a queue. For this, I used Amazon Simple Queue Service (SQS).
Once I had all the WARC file names sent to a queue, I created a few AWS instances. I used spot instances to keep things cheap.
Each instance would start and immediately run a custom script I had provided. This script was the workhorse.
As soon as the EC2 spot instance started, the script would get executed. The script did the following;
- It called the SQS queue and got an item that was waiting in the queue. This item was the
WARCfile name. - It would then download the
WARCfile, uncompress it and process the contents. - The final step was to write the results into an S3 bucket. Writing to S3 meant that all the workers were storing their results in a central place which I could process later.
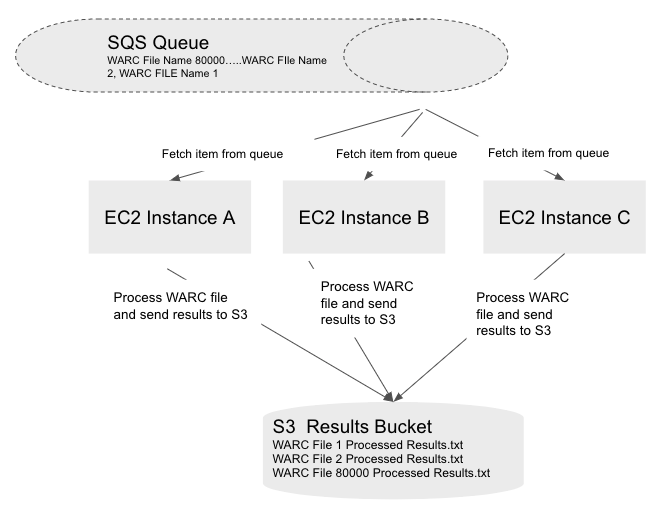
The basic approach is captured in the above diagram.
Sometimes, not using the cloud is a constraint that I like to impose on my side projects.
Why?
It is useful to learn how some of the services that cloud providers offer are actually built.
Many services offered like Kafka or Elasticsearch can be used without using the managed offering. You can just download Elasticsearch or a Postgres database and run it on your local machine.
For example, you can roll your own queue using Kafka or Redis locally.
You can even run Spark locally.
Constraints can force you to get close to these technologies and learn more of the basic building blocks and create familiarity.
The approach I finally settled on was arrived at after much tinkering. One approach I tried early on when I did not want to use the cloud was to use the Redis LIST as a queue.
I loaded up the WARC file names into a Redis LIST and each worker would make a blocking call to fetch an item from the list.
The blocking call ensured that if more than one worker were trying to read from the List, Redis would only process requests one at a time. This ensured that the same item could not be read by more than 1 worker.
The downside of this approach (all on my local machine) was that downloading these massive WARC files hogged my home Internet bandwidth.
Moving to the cloud not only solved the bandwidth issue but allowed me to use a lot more components to make my life easier. Remember, the Common Crawl dataset is hosted on AWS S3 in a specific region. If you run your compute in the same region you do not pay to transfer the CC datasets to your compute resources.
If you choose another region or another cloud, say Google Cloud, then you incur cost to transfer data into your compute resources. This is something to be careful about.