trailblazing_murthy
Now that we have the dataset we want to analyze with BERTopic, we head over to Kaggle and get stated by creating a notebook.
https://www.kaggle.com/code/harshsinghal/cdnjs-packages-json-compile contains code to showcase how BERTopic can be applied to the Javascript descriptions collected from CDNJS Github repostiory.
BERTopic is a really nice Python library. It has great documentation and its interface is very simple.
In the notebook, you can see how easy it was to extract topics and visualize them.
Topic modeling is used across industries and enables businesses to parse unstructured data such as survey responses, product reviews, legal briefs, and patent claims just to name a few.
By applying Topic modeling techniques which leverage modern NLP methods like sentence embeddings (used by BERTopic) businesses are able to find meaningful Topics to further optimize their service and product offerings by learning what their customers are telling them.
In a Topic modeling workflow, you are usually presented with visualizations of the kind shown below.
The algorithm identifies a specific number of topics and for each topic, the top keywords are extracted.
Browsing the keywords below you can easily tell that the topics identified have segmented the Javascript frameworks (based on the description text) into groups that focus on a specific application area.
Topic 6 talks about maps.
Topic 3 is about React and React components.
Topic 8 has identified Javascript libraries that is related to fonts and icons.
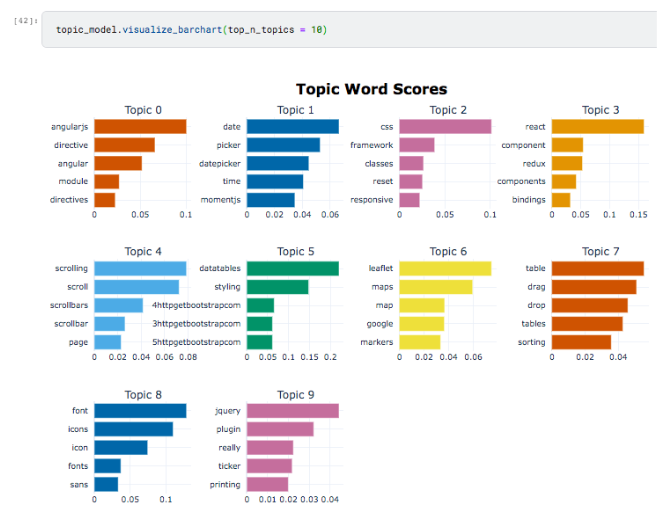
Fascinating!
The visualization below is a quick way to see all the topics and also observe which topics are related.
You can also hover on the plot and see the top keywords for each of the topics.
Very useful.
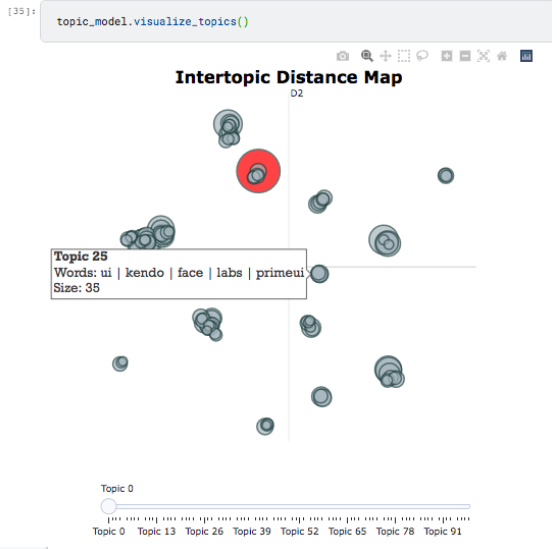
In the notebook, you will learn how to extract the topic name for each of the topics identified.
The name of the topic, assigned automatically by BERTopic is a simple joining of the top keywords. This naming approach is more helpful than calling a topic by a number. Would you choose topic 25 or topic ui_kendo_face_primeui?
My choice is clear!
The next step in my journey was to take all of this information and join it meaningfully.
On the one hand, I have information related to which Javascript libraries are being used by various websites. On the other hand, I have information related to the description of the Javascript library and which Topic it belongs to.
I needed to join these datasets so that I could make sense of all of this information in one place.
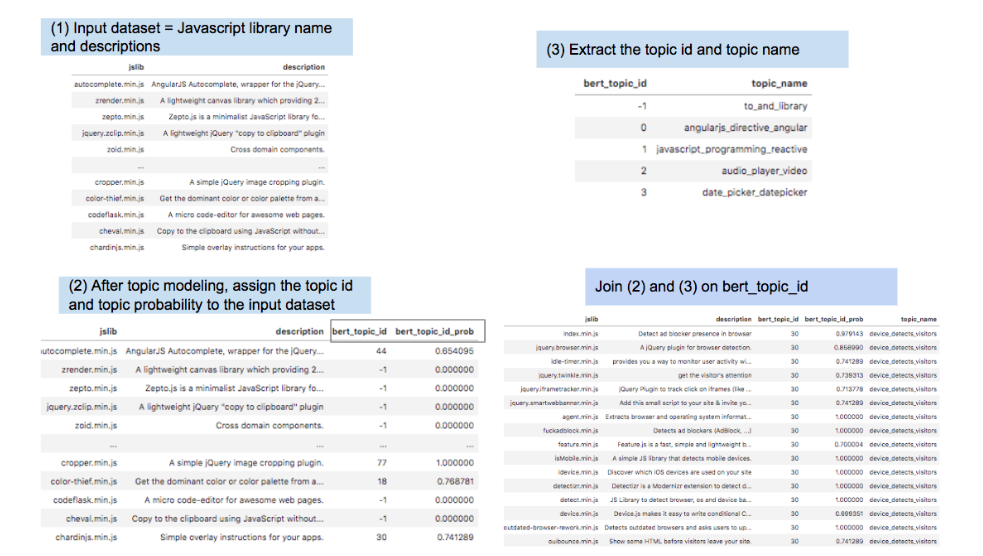
Now we have a dataset that contains the name of the Javascript library, its description, and the topic it has been assigned to.
We already have our original dataset from Common Crawl which identifies the website and the Javascript libraries used.
With the above datasets I created a final dataset which looked like the following;

The Javascript library is accounting.min.js and it is described as a lightweight Javascript library for number, money, and currency formatting.
A sample list of websites are also mentioned where accounting.min.js was detected based on Common Crawl data that we analyzed.
The dataset is in JSON format.
Grab hold of this dataset on Kaggle datasets https://www.kaggle.com/datasets/harshsinghal/javascript-libs-and-description-and-sites-using-it