sweet_sarabhai
After building the prototype and hosting it on my own domain, I wasn’t done.
I had put together the project end-to-end. But I wanted to do more with the data collected. I wanted to analyze it for all sorts of questions.
What were the most popular Javascript libraries? Which libraries occurred frequently together? Which websites were using fingerprinting technology? Was it possible to infer the type of website from its URL? And so on.
How would I know what each Javascript library did? What was it being used for?
And how could I learn more about the website from just the URL?
Putting these two together, I could then profile the website. Based on patterns found in the URL itself and the kinds of Javascript libraries used, a picture may emerge.
To figure out the purpose of the Javascript library, I started sampling a few of the names and looking them up. This was obviously going to be tedious and not something I could scale to even hundreds of libraries.
So I did what I usually do.
I searched for Javascript libraries Github, Javascript libraries descriptions Github and a few other similar keywords.
I found that Github had a ton of Javascript libraries hosted on it. No surprise there.
I could download each of these libraries and then try to match their names with my list and for exact matches, I could just use the information from the README.md file in their Git repositories.
Nah. It was getting too complicated.
I kept thinking.
I knew that Javascript libraries were hosted on CDNs (Content Delivery Networks). Surely these CDN providers would have a single place where I could go and grab this basic information that relates the name of the JS library to its description or purpose.
So I started to look for CDNs that served Javascript libraries.
The first result was cdnjs.com
And I started poking around.
I looked at the About page.
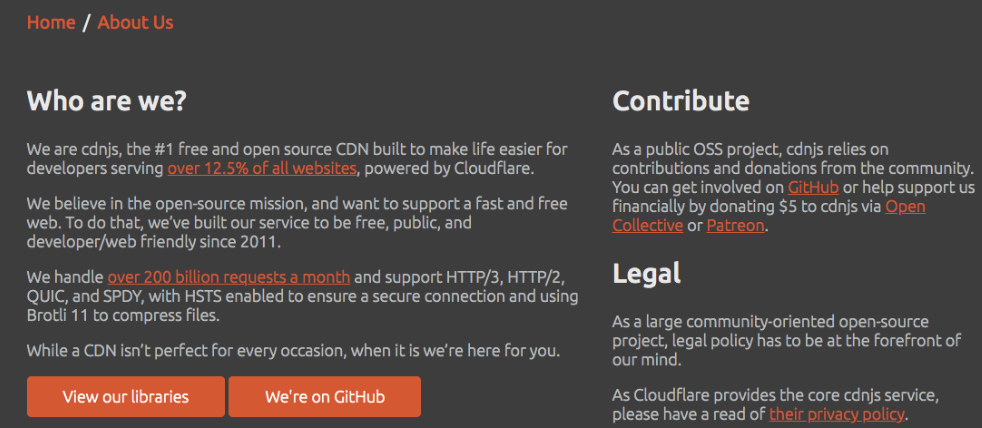
cdnjs.com powers 12.5% of all websites. This is a comprehenisve source of information.
I clicked on View our libraries and saw a list of libraries and description text beneath it.
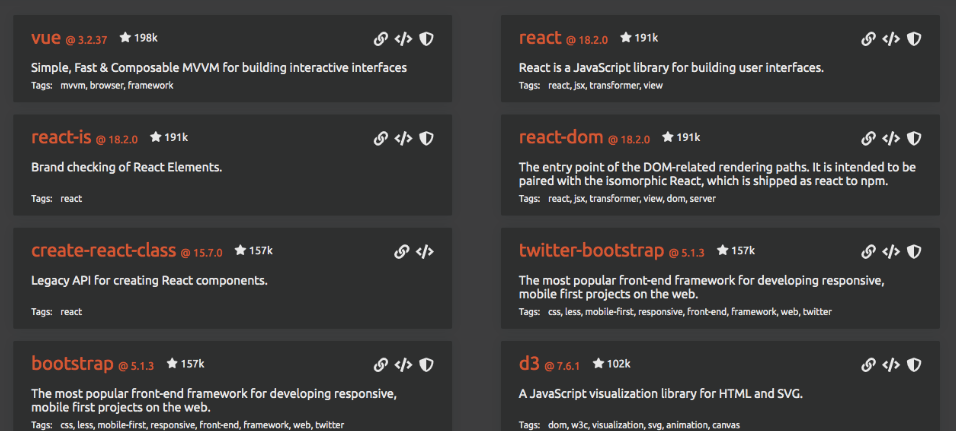
This is exactly what I was looking for.
I hopped over to their Github and started poking around there.
The packages repo seemed interesting.
After clicking through a few times, I found a bunch of directories (arranged alphabetically). Looking into the directory for packages starting with the letter b (I picked b randomly), I came across a list of JSON files.
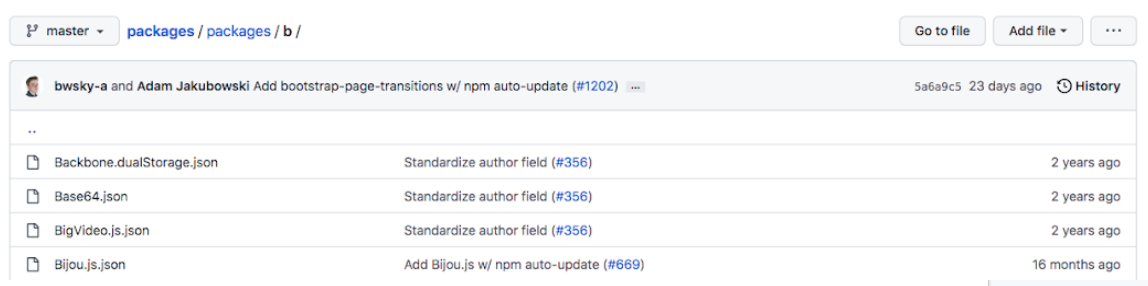
I clicked on Blotter.json (picked randomly).
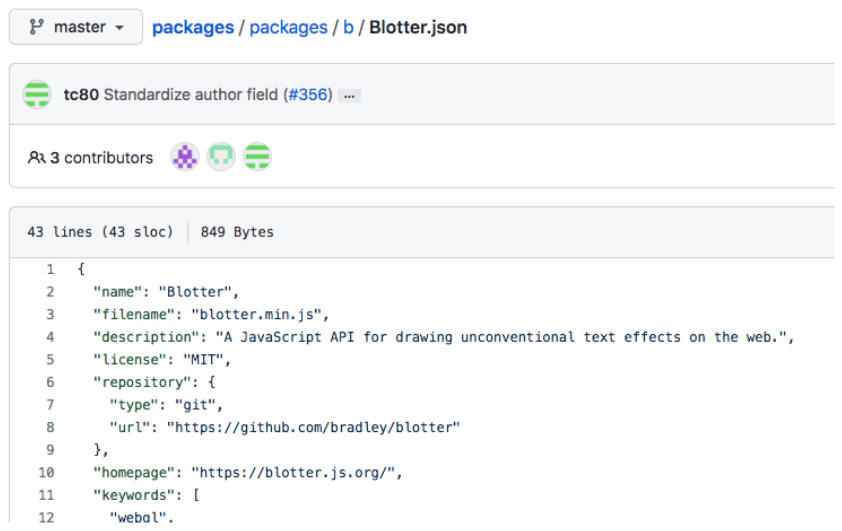
blotter.min.js is a library that can be used for drawing unconventional text effects.
Nice.
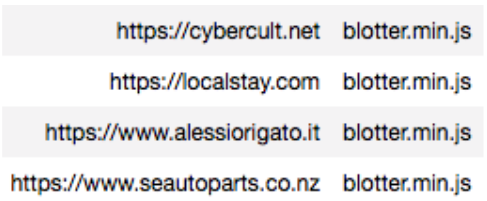
I then checked my dataset if I had any matches for blotter.min.js
I found 4 websites using this library in the dataset I had collected.
I could now figure out the kinds of Javascript libraries I had in my url_js.txt dataset.
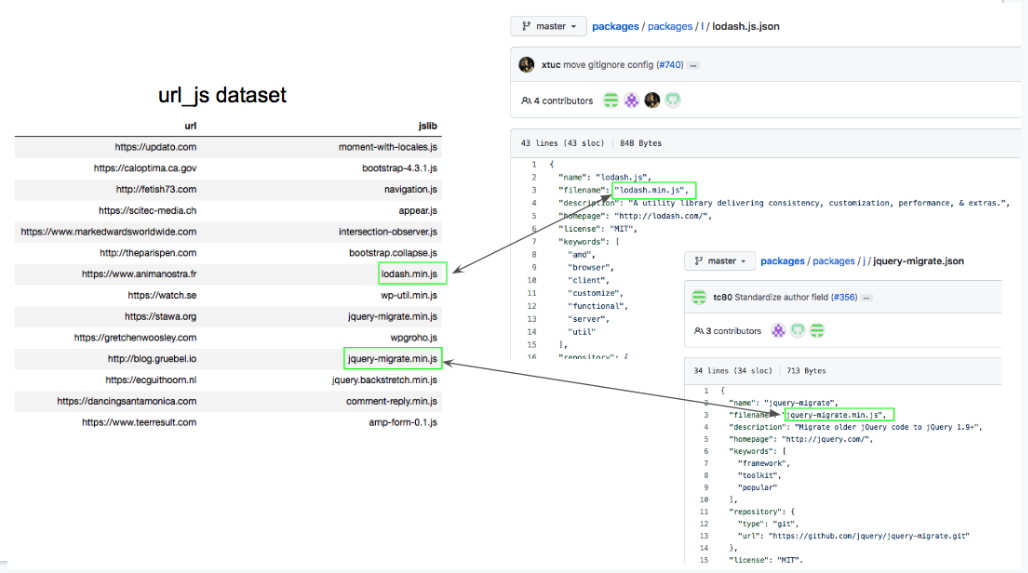
By matching the Javascript library file name in my dataset with the filename field in the JSON files, I could know the description of the Javascript library.
Some of these JSON files also contained a keywords column which could provide additional context and information.
I wanted to compile all these JSON files and create a single dataset.
So I did.
And this is how I did it.
I first cloned https://github.com/cdnjs/packages.git into a Kaggle notebook.
I then walked through all the JSON files, under each of the alphabet directories, in the packages folder. After reading each JSON file, I extracted the filename and description text and compiled it into a Pandas dataframe.
Here is the Kaggle Notebook https://www.kaggle.com/harshsinghal/cdnjs-packages-json-compile where you can follow along the steps outlined above.
And here is what the dataset looks like.

This dataset is a gold mine.
We will analyze the descriptions to find clusters which we can then interpret to find different groups of Javascript libraries.