magical_ramanujam
The urls_js.txt dataset is a gold mine. We can all agree on that.
Now I was beginning to believe that TattleWeb could become a reality. I had the data and now I wanted to develop the product.
It so happened that I had picked up some web application development in college.
During my Masters at Rutgers, I did some work with Perl and CGI programming. Back then, I picked up Perl to scrape some websites and CGI stuff to build a web app to show results to my industry partners funding my thesis project.
This was 2007-2008 and it gave me a huge kick when I developed a web application that displayed the results of my GAMS solver. That is stuff for another book that I'm thinking about writing. At Rutgers I learned a lot of things, and I'm sure those learnings will be of use to other students going abroad for ther Masters.
And while I didn’t do much with Perl and web applications after graduating, I continued to learn web stuff whenever necessary. I had picked up the Flask library and had also tinkered with bottle.py and a few other web frameworks in Python.
JQuery was all the rage in the 2010+ era and I used it to do AJAX. Beyond that, I just did all the HTML using Jinja templates.
So I developed a prototype.
The prototype was barebones. It had a search bar and given an input Javascript library name, it would return the list of websites that contained the input library name being searched.
And it looked like this.
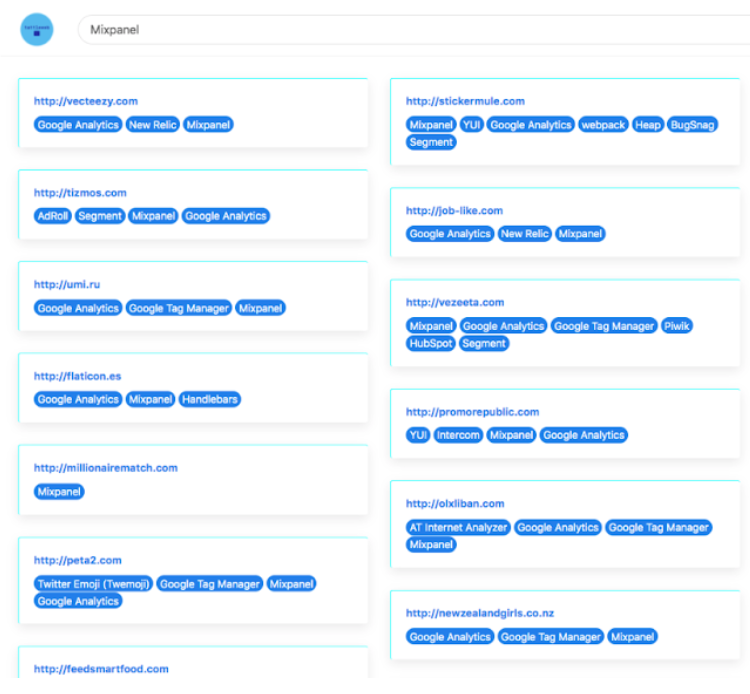
You could search for say, Mixpanel, a popular web analytics product, and would see a list of websites where I found the Mixpanel Javascript library being used.
Each result URL also contained the list of other Javascript libraries that were being used by that site (the blue labels). Each of these labels were clickable.
On clicking the blue label say of Piwik, I would fetch results of all the URLs that used Piwik without a page refresh (using AJAX with JQuery to accomplish this). And so on.
What I thought was missing was more details about each of the Javascript libraries.
A lot of analysis can be done just on the URLs itself. Check out https://www.kaggle.com/code/harshsinghal/common-crawl-url-analysis that analyzes the URLs in very interesting ways.
I will be expanding more on the URL analysis in another chapter.